- Asisten virtual
- Pengolahan bahasa alami
- Model bahasa besar
- Pengenalan karakter optis
- Linguistik komputasi
- AI-komplit
- Pemeriksa ejaan
- Penambangan teks
- Seq2seq
- Attention Is All You Need
- Attention (machine learning)
- Transformer (deep learning architecture)
- Quoc V. Le
- Oriol Vinyals
- Neural machine translation
- Large language model
- Neural network (machine learning)
- History of artificial neural networks
- What's the difference between LSTM and Seq2Seq (M to 1)
- tensorflow - Understanding Seq2Seq model - Stack Overflow
- Install seq2seq on google colaboratory - Stack Overflow
- Where to place <start> and <end> tags in seq2seq translations?
- How can I do prepare data for a seq2seq model? - Stack Overflow
- python - PyTorch's seq2seq tutorial decoder - Stack Overflow
- machine learning - AttributeError: module …
- seq2seq - What are differences between T5 and Bart ... - Stack …
- Error when building seq2seq model with tensorflow
- How does batching work in a seq2seq model in pytorch?
seq2seq
Video: seq2seq







Seq2seq GudangMovies21 Rebahinxxi LK21
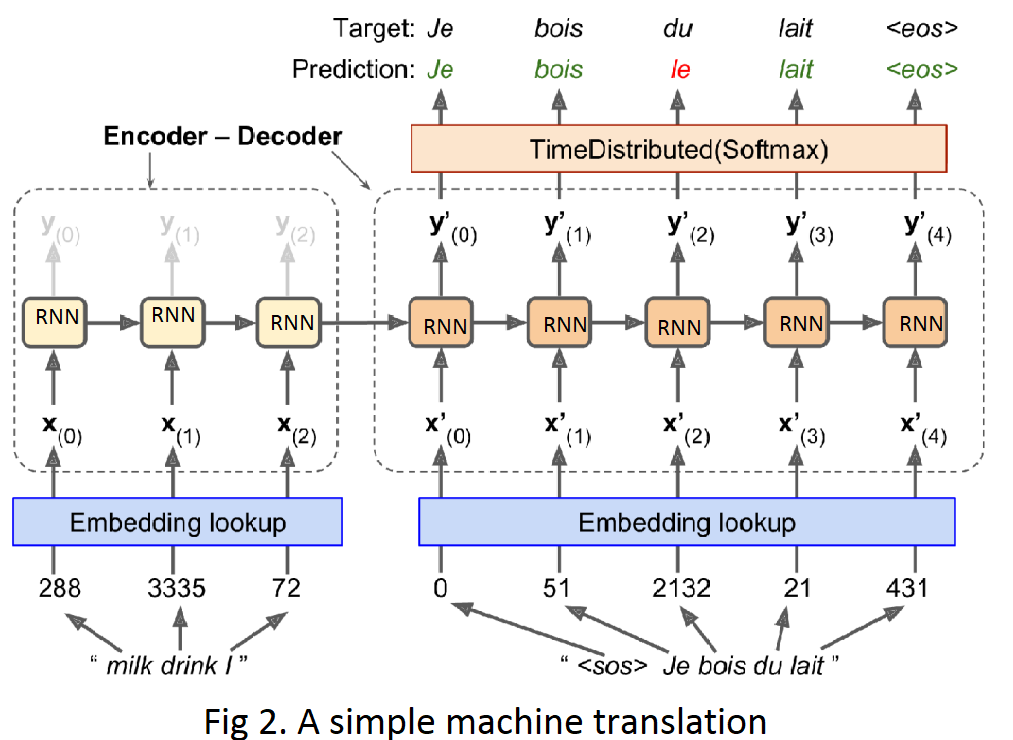
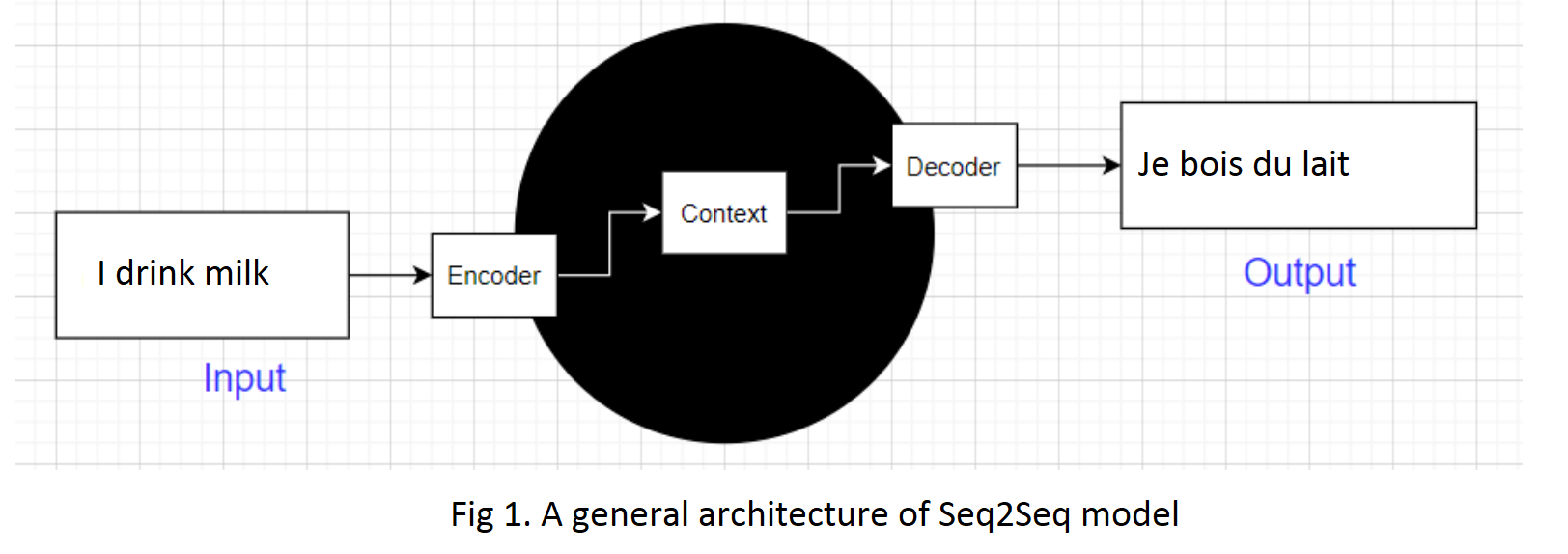
Seq2seq is a family of machine learning approaches used for natural language processing. Applications include language translation, image captioning, conversational models, and text summarization.
Seq2seq uses sequence transformation: it turns one sequence into another sequence.
History
One naturally wonders if the problem of translation could conceivably be treated as a problem in cryptography. When I look at an article in Russian, I say: 'This is really written in English, but it has been coded in some strange symbols. I will now proceed to decode.
seq2seq is an approach to machine translation (or more generally, sequence transduction) with roots in information theory, where communication is understood as an encode-transmit-decode process, and machine translation can be studied as a special case of communication. This viewpoint was elaborated, for example, in the noisy channel model of machine translation.
In practice, seq2seq maps an input sequence into a real-numerical vector by using a neural network (the encoder), and then maps it back to an output sequence using another neural network (the decoder).
The idea of encoder-decoder sequence transduction had been developed in the early 2010s (see for previous papers). The papers most commonly cited as the originators that produced seq2seq are two papers from 2014.
In the seq2seq as proposed by them, both the encoder and the decoder were LSTMs. This had the "bottleneck" problem, since the encoding vector has a fixed size, so for long input sequences, information would tend to be lost, as they are difficult to fit into the fixed-length encoding vector. The attention mechanism, proposed in 2014, resolved the bottleneck problem. They called their model RNNsearch, as it "emulates searching through a source sentence during decoding a translation".
A problem with seq2seq models at this point was that recurrent neural networks are difficult to parallelize. The 2017 publication of Transformers resolved the problem by replacing the encoding RNN with self-attention Transformer blocks ("encoder blocks"), and the decoding RNN with cross-attention causally-masked Transformer blocks ("decoder blocks").
= Priority dispute
=One of the papers cited as the originator for seq2seq is (Sutskever et al 2014), published at Google Brain while they were on Google's machine translation project. The research allowed Google to overhaul Google Translate into Google Neural Machine Translation in 2016. Tomáš Mikolov claims to have developed the idea (before joining Google Brain) of using a "neural language model on pairs of sentences... and then [generating] translation after seeing the first sentence"—which he equates with seq2seq machine translation, and to have mentioned the idea to Ilya Sutskever and Quoc Le (while at Google Brain), who failed to acknowledge him in their paper. Mikolov had worked on RNNLM (using RNN for language modelling) for his PhD thesis, and is more notable for developing word2vec.
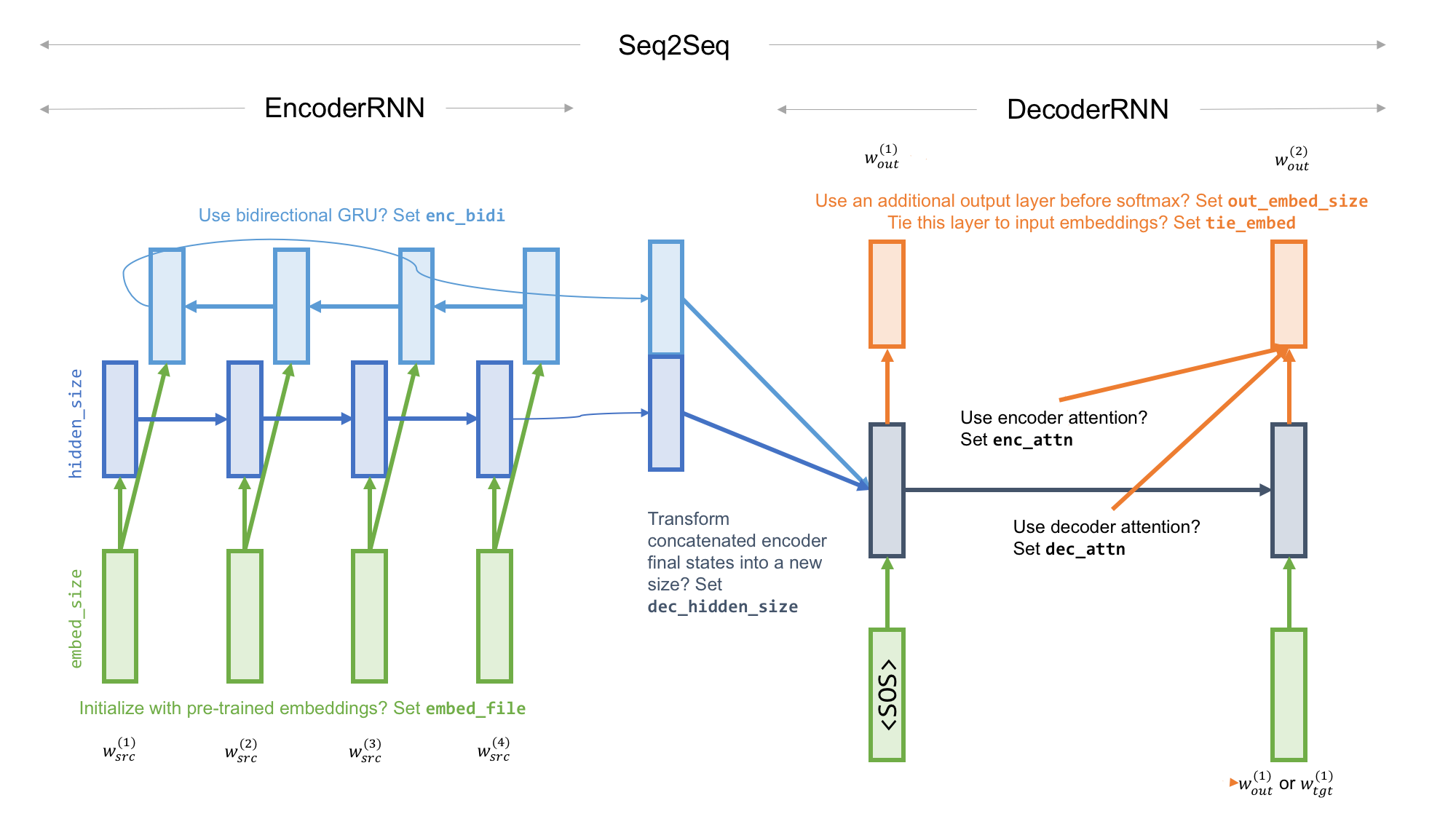
Architecture
= Encoder
=The encoder is responsible for processing the input sequence and capturing its essential information, which is stored as the hidden state of the network and, in a model with attention mechanism, a context vector. The context vector is the weighted sum of the input hidden states and is generated for every time instance in the output sequences.
= Decoder
=The decoder takes the context vector and hidden states from the encoder and generates the final output sequence. The decoder operates in an autoregressive manner, producing one element of the output sequence at a time. At each step, it considers the previously generated elements, the context vector, and the input sequence information to make predictions for the next element in the output sequence. Specifically, in a model with attention mechanism, the context vector and the hidden state are concatenated together to form an attention hidden vector, which is used as an input for the decoder.
= Attention mechanism
=The attention mechanism is an enhancement introduced by Bahdanau et al. in 2014 to address limitations in the basic Seq2Seq architecture where a longer input sequence results in the hidden state output of the encoder becoming irrelevant for the decoder. It enables the model to selectively focus on different parts of the input sequence during the decoding process. At each decoder step, an alignment model calculates the attention score using the current decoder state and all of the attention hidden vectors as input. An alignment model is another neural network model that is trained jointly with the seq2seq model used to calculate how well an input, represented by the hidden state, matches with the previous output, represented by attention hidden state. A softmax function is then applied to the attention score to get the attention weight.
In some models, the encoder states are directly fed into an activation function, removing the need for alignment model. An activation function receives one decoder state and one encoder state and returns a scalar value of their relevance.
Other applications
In 2019, Facebook announced its use in symbolic integration and resolution of differential equations. The company claimed that it could solve complex equations more rapidly and with greater accuracy than commercial solutions such as Mathematica, MATLAB and Maple. First, the equation is parsed into a tree structure to avoid notational idiosyncrasies. An LSTM neural network then applies its standard pattern recognition facilities to process the tree.
In 2020, Google released Meena, a 2.6 billion parameter seq2seq-based chatbot trained on a 341 GB data set. Google claimed that the chatbot has 1.7 times greater model capacity than OpenAI's GPT-2, whose May 2020 successor, the 175 billion parameter GPT-3, trained on a "45TB dataset of plaintext words (45,000 GB) that was ... filtered down to 570 GB."
In 2022, Amazon introduced AlexaTM 20B, a moderate-sized (20 billion parameter) seq2seq language model. It uses an encoder-decoder to accomplish few-shot learning. The encoder outputs a representation of the input that the decoder uses as input to perform a specific task, such as translating the input into another language. The model outperforms the much larger GPT-3 in language translation and summarization. Training mixes denoising (appropriately inserting missing text in strings) and causal-language-modeling (meaningfully extending an input text). It allows adding features across different languages without massive training workflows. AlexaTM 20B achieved state-of-the-art performance in few-shot-learning tasks across all Flores-101 language pairs, outperforming GPT-3 on several tasks.
See also
Artificial neural network
References
External links
"A ten-minute introduction to sequence-to-sequence learning in Keras". blog.keras.io. Retrieved 2019-12-19.
Adiwardana, Daniel; Luong, Minh-Thang; So, David R.; Hall, Jamie; Fiedel, Noah; Thoppilan, Romal; Yang, Zi; Kulshreshtha, Apoorv; Nemade, Gaurav; Lu, Yifeng; Le, Quoc V. (2020-01-31). "Towards a Human-like Open-Domain Chatbot". arXiv:2001.09977 [cs.CL].
Kata Kunci Pencarian: seq2seq
seq2seq
Daftar Isi
What's the difference between LSTM and Seq2Seq (M to 1)
Mar 23, 2021 · Seq2seq is a family of machine learning approaches used for language processing. Applications include language translation, image captioning, conversational models and text summarization. ... Seq2seq turns one sequence into another sequence.
tensorflow - Understanding Seq2Seq model - Stack Overflow
Sep 22, 2017 · In seq2seq source code, you can find the following code in basic_rnn_seq2seq(): _, enc_state = rnn.static_rnn(enc_cell, encoder_inputs, dtype=dtype) return rnn_decoder(decoder_inputs, enc_state, cell) If you use an LSTMCell, the returned enc_state from the encoder will be a tuple (c, h). As you can see, the tuple is passed directly to the decoder.
Install seq2seq on google colaboratory - Stack Overflow
May 24, 2018 · I have installed seq2seq on google colab but when I want to import it I get the error: **no module named "seq2seq"** When I run: !python3 drive/app/seq2seq-master/setup.py build !python3 drive/app/seq2seq-master/setup.py install import seq2seq How do I import seq2seq correctly in this environment?
Where to place <start> and <end> tags in seq2seq translations?
Mar 12, 2019 · So, for seq2seq model ( English to French translation ), I have encoder_input_data which has English phrases without <start> and <stop> tags. I am confused with the decoder_input_data and decoder_target_data. Currently, my data is organized in such a manner which results in nothing.
How can I do prepare data for a seq2seq model? - Stack Overflow
Nov 25, 2019 · I've seen the keras seq2seq-lstm example and I couldn't understand how to prepare data from text, this is the for loop used for preparing data. But I couldn't understand few things in it. But I couldn't understand few things in it.
python - PyTorch's seq2seq tutorial decoder - Stack Overflow
Feb 4, 2025 · It is about "Teacher Forcing" which is a trainign technique for seq2seq. While teacher forcing it learns and when no theacher forcing it interferes( makes guesses.) So what is the realaiton with the shape? Since decoder generates one token at time for each token in batch it needs (batch_size, 1) with 2D shape.
machine learning - AttributeError: module …
Feb 23, 2020 · AttributeError: module 'tensorflow.contrib.seq2seq' has no attribute 'prepare_attention' I updated my tensorflow version to 1.0.0. But the up-gradation did not solved my problem. I also searched in google regarding this error, but i did not got correct solution. Here is the code part, please have a look. Getting the training and test predictions
seq2seq - What are differences between T5 and Bart ... - Stack …
Dec 29, 2023 · Similarity: Both models are encoder-decoder models. Both models are suitable for most seq2seq tasks such as summarization, translation QA tasks, comprehension tasks, etc. Both of them issued in 2019) T5 by Google, BART by Facebook AI. Differences: pretraining objective:
Error when building seq2seq model with tensorflow
Most of the models (seq2seq is not an exception) expect their input to be in batches, so if the shape of your logical input is [n], then a shape of a tensor you will be using as an input to your model should be [batch_size x n].
How does batching work in a seq2seq model in pytorch?
Mar 14, 2018 · I am trying to implement a seq2seq model in Pytorch and I am having some problem with the batching. For example I have a batch of data whose dimensions are [batch_size, sequence_lengths, encoding_dimension] where the sequence lengths are different for each example in the batch.