- Apache Flink
- Daftar kata yang dilindungi di SQL
- Nested loop join
- Hash join
- Block nested loop
- Join (SQL)
- Sort-merge join
- Ingres (database)
- Query plan
- List of algorithms
- Adaptive Server Enterprise
- Correlated subquery
nested loop join



























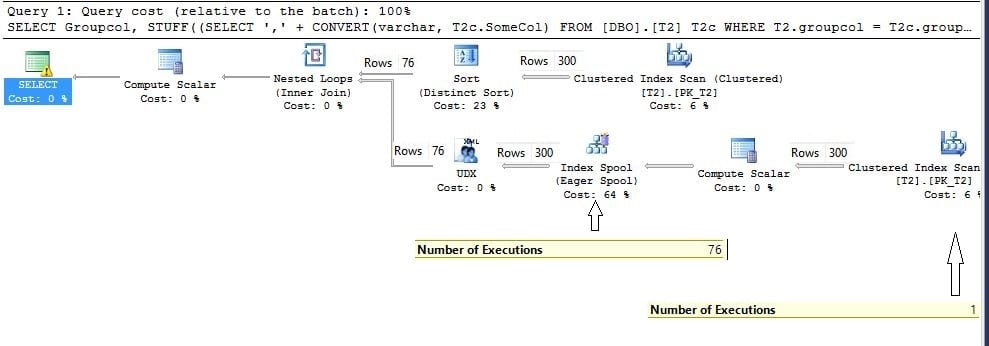







Nested loop join GudangMovies21 Rebahinxxi LK21
A nested loop join is a naive algorithm that joins two relations by using two nested loops. Join operations are important for database management.
Algorithm
Two relations
R
{\displaystyle R}
and
S
{\displaystyle S}
are joined as follows:
algorithm nested_loop_join is
for each tuple r in R do
for each tuple s in S do
if r and s satisfy the join condition then
yield tuple
This algorithm will involve nr*bs+ br block transfers and nr+br seeks, where br and bs are number of blocks in relations R and S respectively, and nr is the number of tuples in relation R.
The algorithm runs in
O
(
|
R
|
|
S
|
)
{\displaystyle O(|R||S|)}
I/Os, where
|
R
|
{\displaystyle |R|}
and
|
S
|
{\displaystyle |S|}
is the number of tuples contained in
R
{\displaystyle R}
and
S
{\displaystyle S}
respectively and can easily be generalized to join any number of relations ...
The block nested loop join algorithm is a generalization of the simple nested loops algorithm that takes advantage of additional memory to reduce the number of times that the
S
{\displaystyle S}
relation is scanned. It loads large chunks of relation R into main memory. For each chunk, it scans S and evaluates the join condition on all tuple pairs, currently in memory. This reduces the number of times S is scanned to once per chunk.
Index join variation
If the inner relation has an index on the attributes used in the join, then the naive nest loop join can be replaced with an index join.
algorithm index_join is
for each tuple r in R do
for each tuple s in S in the index lookup do
yield tuple
The time complexity for this variation improves from
O
(
|
R
|
|
S
|
)
to
O
(
|
R
|
log
|
S
|
)
{\displaystyle O(|R||S|){\text{ to }}O(|R|\log |S|)}
See also
Hash join
Sort-merge join